The Fallacy of the Right Answer is everywhere. With regards to education technology, it dates back at least to BF Skinner.
Skinner saw education as a series of definite, discrete, linear steps along a fixed, straight road; today this is called a curriculum. He referred to a child who guesses the password as “being right”. Khan Academy uses similar gatekeeping techniques in its exercises, limiting the context. Students must meet one criterion before proceeding to the next, being spoon-fed knowledge and seeing through a peephole not unlike Skinner’s machines. Furthermore, these steps are claimed to be objective, universal and emotionless. Paul Lockhart calls this the “ladder myth”, the conception of mathematics as a clear hierarchy of dependencies. But the learning hierarchy is tangled, replete with strange loops.
It is fallacious yet popular to think that a concept, once learned, is never forgotten. But most educated adults I know (including myself) find value in rereading old material, and make connections back to what they already have learned. What was once understood narrowly or mechanically can, when revisited, be understood in a larger or more abstract context, or with new cognitive tools. There are two words for “to know” in French. Savoir means to know a fact, while connaitre means to be familiar with, comfortable with, to know a person. The Right Answer loses sight of the importance, even the possibility, of knowing a piece of information like an old friend, to find pleasure in knowing, to know for knowing’s sake, because you want to. Linear teaching is workable for teaching competencies but not for teaching insights, things like why those mechanical methods work, how they can be extended, and how they can fail.
I feel like somewhere along the way, we decided we loved Speak & Spell more than Logo and that still informs ed-tech today
— Audrey Watters (@audreywatters) June 24, 2014
Symbol manipulation according to fixed rules is not cognition but computation. The learners take on the properties of the machines, and those who programmed them. As Papert observed, the computer programs the child, not the other way around (as he prefers). Much of this mechanical emphasis is driven by the SAT and other unreasonable standardized tests which are nothing more than timed high-stakes guessing games. They are gatekeepers to the promised land of College. Proponents of education reform frequently cite distinct age-based grades as legacy of the “factory line model” dating back to the industrial revolution. This model permeates not only how we raise children, but more importantly, what we raise them to do, what we consider necessary of an educated adult. Raising children to work machinery is the same as, or has given way to, raising them to work like machinery. Tests like the SAT emphasize that we should do reproducible de-individualized work, compared against a clear, ideal, unachievable standard. Putting this methodology online does not constitute a revolution or disruption.

(source)
Futurists have gone as far to see the brain itself as programmable, in some mysteriously objective sense. At some point, Nicholas Negroponte veered off his illustrious decades-long path. Despite collaborating with Seymour Papert at the Media Lab, his recent work has been dropping tablets into rural villages. Instant education, just add internet! It’s great that the kids are teaching themselves, and have some autonomy, but who designed the apps they play with? What sort of biases and fallacies do they harbor? Do African children learning the ABCs qualify as cultural imperialism? His prediction for the next thirty years is even more troublesome: that we’ll acquire knowledge by ingesting it. Shakespeare will be encoded into some nano-molecular device that works its way through the blood-brain barrier, and suddenly: “I know King Lear!”. Even if we could isolate the exact neurobiological processes that constitute reading the Bard, we all understand Shakespeare in different ways. All minds are unique, and therefore all brains are unique. Meanwhile, our eyes have spent a few hundred million years of evolutionary time adapting to carry information from the outside world into our mind at the speed of an ethernet connection. Knowledge intake is limited not by perception but by cognition.
Tufte says, to simplify, add context. Confusion is not a property of information but of how it is displayed. He said these things in the context of information graphics but they apply to education as well. We are so concerned with information overload that we forget information underload, where our brain is starved for detail and context. It is not any particular fact, but the connections between them, that constitute knowledge. The fallacy of reductionism is to insist that every detail matters: learn these things and then you are educated! The fallacy of holism is to say that no details matter: let’s just export amorphous nebulous college-ness and call it universal education! Bret Victor imagines how we could use technology to move from a contrived, narrow problem into a deeper understanding about generalized, abstract notions, much as real mathematicians do. He also presents a mental model for working on a difficult problem:
I’m trying to build a jigsaw puzzle. I wish I could show you what it will be, but the picture isn’t on the box. But I can show you some of the pieces… If you are building a different puzzle, it’s possible these pieces won’t mean much to you. You might not have a spot for them to fit, or you might not yet. On the other hand, maybe some of these are just the pieces you’ve been looking for.
One concern with Skinner’s teaching machines and their modern-day counterparts is that they isolate each student and cut off human interaction. We learn from each other, and many of the things that we learn fall outside of the curriculum ladder. Learning to share becomes working on a team; show-and-tell becomes leadership. Years later, in college, many of the most valuable lessons are unplanned, a result of meeting a person with very different ideas, or hearing exactly what you needed to at that moment. I found that college exposed to me brilliant people, and I could watch them analyze and discuss a problem. The methodology was much more valuable than the answer it happened to yield.
The hallmark of an intellectual is do create daily what has never existed before. This can be an engineer’s workpiece, an programmer’s software, a writer’s novel, a researcher’s paper, or an artist’s sculpture. None of these can be evaluated by comparing them to a correct answer, because the correct answer is not known, or can’t even exist. The creative intellectual must have something to say and know how to say it; ideas and execution must both be present. The bits and pieces of a curriculum can make for a good technician (a term I’ve heard applied to a poet capable of choosing the exact word). It’s not so much that “schools kill creativity” so much as they replace the desire to create with the ability to create. Ideally schools would nurture and refine the former (assuming something-to-say is mostly innate) while instructing the latter (assuming saying-it-well is mostly taught).
What would a society look like in which everyone was this kind of intellectual? If everyone is writing and drawing, who will take out the trash, harvest food, etc? Huxley says all Alphas and no Epsilons doesn’t work. Like the American South adjusting to an economy without slaves, elevating human dignity leaves us with the question of who will do the undignified work. As much as we say that every child deserves an education, I think that the creative intellectual will remain in an elite minority for years to come, with society continuing to run on the physical labor of the uneducated. If civilization ever truly extends education to all, then either we will need to find some equitable way of sharing the dirty work (akin to utopian socialist communes), or we’ll invent highly advanced robots. Otherwise, we may need to ask ourselves a very unsettling question: can we really afford to extend education to all, given the importance of unskilled labor to keep society running?
If you liked this post, you should go read everything Audrey Watters has written. She has my thanks.
 will give you the circle I asked for. But that’s only because you memorized it. Why this formula? It’s not obvious that it should be a circle. It doesn’t feel very circular, unless you fully understand the abstraction beneath it (in this case, the Pythagorean theorem) and how it applies to the situation.
will give you the circle I asked for. But that’s only because you memorized it. Why this formula? It’s not obvious that it should be a circle. It doesn’t feel very circular, unless you fully understand the abstraction beneath it (in this case, the Pythagorean theorem) and how it applies to the situation.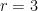 and we’re done. It’s not a compromise between the human and the technology, it’s an abstraction – doing something more elegant and concise than either native form. Human and technology alike stretch to accommodate the new representation. Abstractions aren’t fuzzy and amorphous. Abstractions are crisp, and stacked on top of each other, like new shirts in a store.
and we’re done. It’s not a compromise between the human and the technology, it’s an abstraction – doing something more elegant and concise than either native form. Human and technology alike stretch to accommodate the new representation. Abstractions aren’t fuzzy and amorphous. Abstractions are crisp, and stacked on top of each other, like new shirts in a store. and the lack of other information. It’s been maximally compressed (related technical term:
and the lack of other information. It’s been maximally compressed (related technical term: 
{kind=link}